-
Vijit
- June 25, 2026
- No categories assigned.
- No Comments
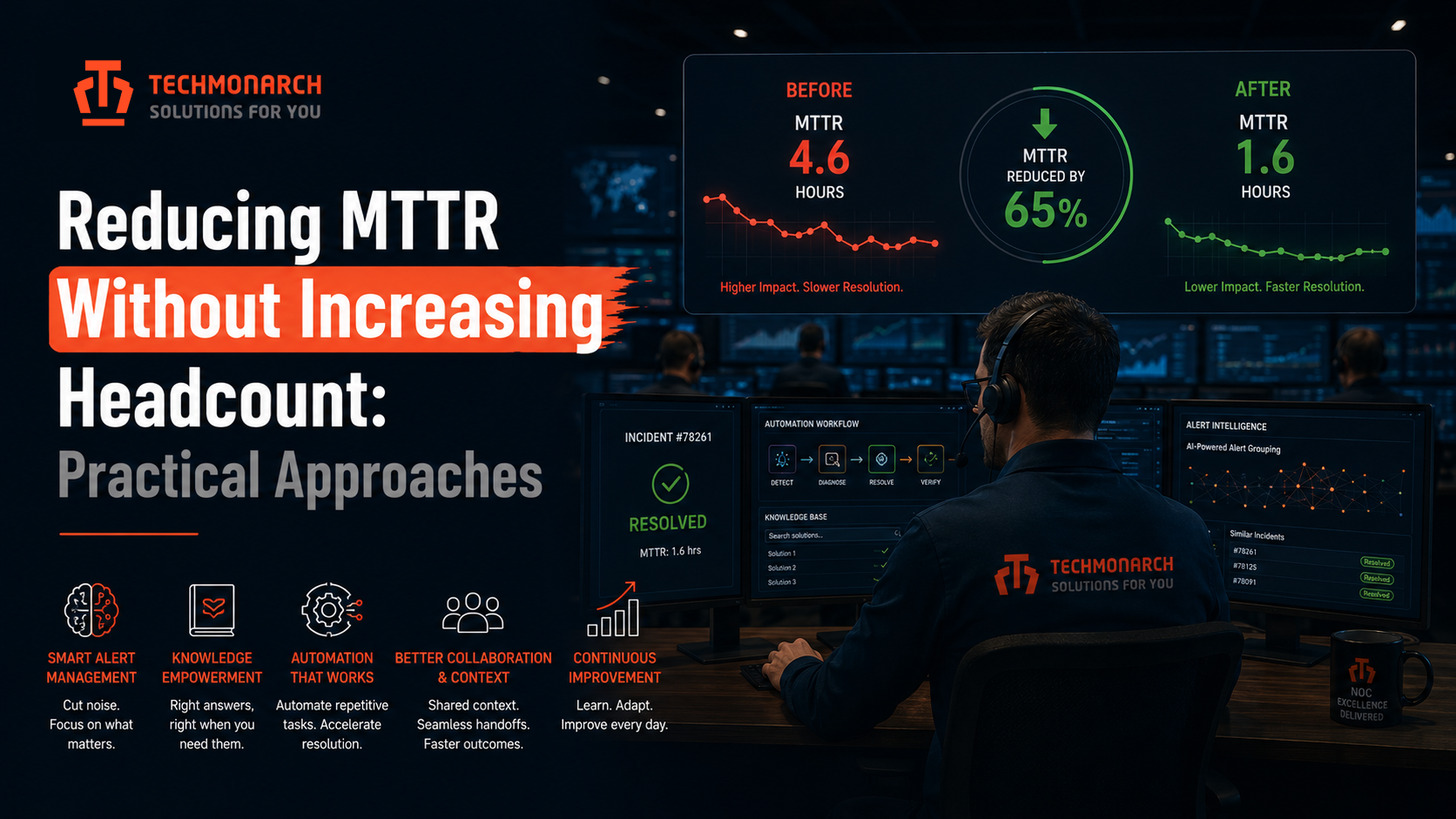
When hiring more engineers is not the answer — and what actually moves the needle on resolution time.
The pressure to improve Mean Time to Resolution is a constant in managed IT service delivery, and the default response to it is almost always the same: hire more engineers, expand the team, increase coverage. It is an understandable instinct. When resolution times creep up, it feels like a capacity problem — not enough people to handle the volume. The trouble is that MTTR is rarely a headcount problem. It is almost always a process problem, a tooling problem, or a knowledge architecture problem. More people inserted into a broken resolution workflow do not resolve incidents faster. They resolve them at the same speed, just in higher volume.
For IT service delivery leaders, NOC managers, and MSP operators who have been around long enough to have tried the headcount approach — and watched it fail to produce the MTTR improvement it promised — the more useful conversation is about what actually works. The practical, non-obvious approaches that move resolution time without requiring a larger payroll.
The following is that conversation.
Diagnose the MTTR Problem Before You Treat It
The single most common mistake in MTTR reduction efforts is skipping the diagnostic step. Teams identify that resolution time is too high and immediately move to solutions — more automation, better tooling, additional training — without first understanding where in the resolution lifecycle the time is actually being lost. MTTR is a composite metric, and it hides a great deal of variation inside a single number.
A meaningful MTTR diagnosis breaks the resolution cycle into its constituent stages: detection, triage and classification, investigation and diagnosis, remediation, and verification. Time lost in each stage has a different cause and a different fix. An operation where detection is slow — where the monitoring layer consistently lags the actual onset of a problem — has a coverage and threshold problem. An operation where detection is fast but triage is slow has a routing and classification problem. An operation where incidents reach the right engineer quickly but resolution still takes too long has a knowledge or tooling problem at the resolution stage.
Improving MTTR without this diagnostic clarity is like treating a fever without checking what is causing it. The symptom might temporarily improve while the underlying problem compounds. Map where the time is going before deciding where to invest.
Eliminate the Context-Reconstruction Tax
One of the least-discussed contributors to slow resolution is the time engineers spend reconstructing context before they can begin solving the problem. An alert fires. A ticket opens. The engineer assigned to it has to determine: what is this system, which client does it belong to, what is the normal baseline for this metric, has this happened before, and if so how was it resolved? In environments where that information is fragmented across multiple tools, the answer to each question requires separate lookups. The actual diagnostic work has not begun yet, and already ten to fifteen minutes have elapsed.
This is not a staffing problem. Adding engineers does not make context reconstruction faster — it just adds more people doing it slowly. The fix is architectural: build the alert and ticket environment so that the answer to every standard context question is attached to the incident before an engineer touches it.
This means alerts that arrive with client environment metadata already populated — asset criticality, ownership, recent change history, and any relevant runbook links — rather than requiring the engineer to retrieve those from separate systems. It means RMM-to-PSA integration that creates tickets with pre-populated context rather than blank forms. It means a monitoring layer configured to include historical behavior data in the alert payload, so the engineer can immediately compare current readings against the established baseline without running a separate query. The diagnostic work that matters starts immediately when context reconstruction is handled systematically rather than ad hoc.
Runbook Depth and Scope: The Most Underutilized MTTR Lever
Runbooks are the most consistently underinvested MTTR lever available to IT service operations, and the reason for that underinvestment is predictable: building good runbooks takes time that teams feel they do not have, so the runbook library stays shallow while the team handles incidents manually, repeatedly, at the same pace.
The value of a well-maintained runbook library is not just speed — it is consistency. An incident type that every engineer handles using the same documented procedure is resolved in approximately the same time, every time, regardless of which engineer is assigned. An incident type that every engineer handles using their own mental model is resolved in wildly variable time, depending on who happens to be on shift. Variability in resolution time is MTTR’s most insidious driver, because it is invisible in the average.
The categories worth prioritizing first:
High-frequency recurring incidents — the most commonly seen failure types across client environments — represent the highest-return runbook investment. If your team handles the same class of incidents twenty times a week and each one requires manual diagnostic steps that could be scripted, the accumulated time loss across those twenty incidents is substantial. Standardized, tested runbooks that walk Tier 1 engineers through the exact diagnostic and remediation steps for these patterns directly reduce escalation rates, which is where a significant portion of MTTR comes from: the time between a Tier 1 engineer recognizing they cannot resolve something and a Tier 2 engineer actually beginning to work on it.
Client-specific runbooks for each client’s most common failure patterns, environment-specific procedures, and maintenance window behaviors are the next layer. These require per-client knowledge to build but dramatically compress resolution time for incidents that would otherwise require the engineer to reason through an unfamiliar environment during the incident itself. The per-client context that lives in a senior engineer’s head needs to be systematically extracted into documentation before that engineer transitions off the account.
Automation Targeted at the Right Stages
Automation for MTTR reduction is most effective when it is targeted at the stages where time is predictably lost, not applied broadly in the hope that it speeds things up generally. There are three stages where automation delivers the highest return:
Automated diagnostics at alert time.
The largest single component of MTTR in most IT environments is triage time — the period between when an incident is identified and when an engineer has enough information to begin working toward resolution. Automated diagnostic data collection at the moment an alert triggers eliminates this lag. Logs, process states, thread dumps, disk I/O statistics, network connection tables — the data that an engineer would otherwise spend ten to twenty minutes collecting manually is attached to the alert before human eyes touch it. Engineers move directly to interpretation and action rather than starting with data collection. In environments with high alert volume, this compression at the triage stage compounds significantly across a shift.
Auto-remediation for known, well-bounded failure patterns.
A meaningful proportion of incidents in mature IT environments are recurring, predictable, and follow a consistent resolution path. Services that fail and restart cleanly. Disk thresholds that are cleared by log rotation. Connectivity interruptions that resolve with an interface cycle. These incidents do not require human judgment — they require execution of a known procedure. Automating that execution eliminates the resolution time entirely for that class of incident, rather than just compressing it. The implementation risk is real: automation that fires on ambiguous conditions, or that attempts remediation in novel situations where the pattern match is imprecise, creates more problems than it solves. The design principle is tight scope — automate the incident types where the failure mode is well-understood, the resolution procedure is tested, and the blast radius of a failed auto-remediation is contained.
Intelligent alert routing and prioritization.
Routing the right incident to the right engineer at the right tier sounds like a process problem, and it is — but it is also an automation problem. In environments where alert routing is handled manually or through coarse classification rules, misrouting is common. A storage incident lands in a network queue. A Windows Server event gets routed to a Linux engineer. A P2 incident sits in a general queue because the initial classification did not capture the asset criticality correctly. Each of these routing errors adds to MTTR not because the eventual resolution is slow, but because time elapses before the resolution work even begins. Automation that routes based on asset type, client tier, incident category, and current engineer workload reduces this pre-resolution delay at scale.
For MSPs that want these capabilities without the overhead of building and maintaining them independently, white-label NOC partnerships offer a practical path. Techmonarch (techmonarch.com) provides white-label NOC services to MSPs globally — operating with the process depth, runbook infrastructure, and automation tooling that compresses MTTR at every stage of the resolution cycle, under the partner’s brand.
Escalation Design: Cutting the Wait Time Between Tiers
Escalation time — the period between a Tier 1 engineer recognizing they need Tier 2 involvement and that Tier 2 engineer actively beginning work — is one of the most overlooked MTTR contributors. In some operations, this window is five minutes. In others, it is forty-five. The difference is almost entirely in escalation process design, not in the competence of the engineers involved.
Escalation paths that are frictionless and well-defined compress this window substantially. An engineer who knows exactly who to contact, through which channel, with what information already compiled, can complete an escalation in under two minutes. An engineer who has to decide who to contact, find that person’s availability, compose a context summary from scratch, and then wait for acknowledgment can easily spend fifteen to twenty minutes in the escalation process itself before Tier 2 begins work.
The operational changes that produce faster escalation are not technically complex: a documented escalation matrix by incident type and severity, a standard escalation template that specifies what context Tier 1 must include, and explicit response time expectations for escalation acknowledgment that are tracked and enforced. None of this requires additional headcount. It requires process discipline and the organizational commitment to measure escalation time as a distinct metric rather than letting it disappear inside the aggregate MTTR number.
Knowledge Continuity Across Shifts and Engineers
MTTR spikes during shift transitions. This is not coincidental. The engineer who inherits an open incident mid-investigation starts from an information deficit — they know what the ticket notes say, which is rarely the full picture of what the previous engineer actually observed and attempted. Reconstructing that context before productive work can resume is a hidden MTTR cost that shows up consistently in operations with high incident carryover rates across shifts.
The fix is documentation standards with real teeth. Not documentation guidelines that engineers are asked to follow — documentation expectations that are treated as a quality standard with the same weight as resolution time. Incident notes should capture not just what was done but what was observed, what hypotheses were tested, what was ruled out, and what the working theory is at handoff. An engineer picking up a mid-investigation incident with that information can begin where the last engineer left off rather than from the beginning.
Pair this with a structured handoff process at shift transitions — a brief written summary of open incidents, their current status, and any time-sensitive items — and the MTTR cost of shift boundaries drops significantly. The time investment is five to ten minutes of documentation per incident at handoff. The return is the elimination of redundant investigation work that could easily consume thirty to sixty minutes on a complex ticket.
Measuring What You Are Actually Trying to Improve
MTTR as a single headline metric is too coarse to drive meaningful improvement. The operations that successfully reduce resolution time track it at the component level: time to detect, time to triage, time from triage to active investigation, time from investigation start to resolution. Each of these sub-metrics points to a specific part of the workflow, and improvement in any one of them produces a corresponding improvement in the overall MTTR number.
Tier 1 resolution rate — the percentage of incidents closed without escalation — is the proxy metric for runbook and knowledge base effectiveness. If this number is not improving over time, the runbook investment is not working or is not being made. Escalation response time tracks the pre-resolution lag discussed above. Repeat incident rate — the proportion of incidents that are reoccurrences of a previously resolved failure type — is the metric that tells you whether root cause analysis and permanent fixes are actually happening or whether the team is papering over recurring problems with temporary resolutions.
The top-performing MSPs in the industry — those maintaining average MTTR under 90 minutes across incident types — are consistently measuring at this level of granularity. The measurement itself does not reduce MTTR. But it surfaces exactly where the time is going, which makes the path to improvement legible rather than speculative.

The Underlying Principle
Every practical approach to MTTR reduction described here shares a common logic: they remove time from the resolution process by eliminating steps that do not require human judgment — context reconstruction, manual data collection, repeated handling of known failure patterns, waiting for escalation acknowledgment — and by ensuring that when human judgment is required, the engineer has everything needed to exercise it immediately.
More engineers in the resolution workflow adds capacity. It does not remove steps. The two are not the same thing, and conflating them is where most MTTR improvement initiatives go wrong. The question worth asking of any MTTR reduction effort is not ‘do we need more people to resolve incidents faster?’ It is ‘what is actually consuming the time between incident onset and resolution, and which of those time consumers can be eliminated by improving how the work is structured?’ That question leads to a different set of answers — and a better outcome.
Recent Posts
- Reducing MTTR Without Increasing Headcount: Practical Approaches
- What a High-Performance NOC Looks Like (Beyond Monitoring)
- Alert Fatigue Is Killing Your NOC Efficiency — Here's What Actually Works
- Why '24/7 Support' Often Fails to Deliver a 24/7 Experience
- The Quality Drop Problem in After-Hours Support (And Why It Happens)
Recent Comments
- No comments to show